La haute disponibilité (HA) fait référence à la capacité d’un système, d’une application ou d’un service informatique à rester opérationnel et accessible pour les utilisateurs, même en présence de pannes, d’incidents ou de défaillances. L’objectif principal de la haute disponibilité est d’assurer la continuité des opérations et de minimiser les interruptions ou les temps d’arrêt.
La haute disponibilité est essentielle dans de nombreux domaines, tels que les services bancaires en ligne, les sites de commerce électronique, les systèmes de réservation, les centres de données, les réseaux informatiques et les infrastructures critiques. Voici quelques-unes des raisons pour lesquelles la haute disponibilité est importante.
Continuité des opérations : La haute disponibilité garantit que les services et les systèmes restent opérationnels même en cas de pannes matérielles, de pannes de logiciels, de cyberattaques ou d’autres problèmes techniques. Cela permet aux entreprises de maintenir leurs activités sans interruptions majeures, ce qui est crucial pour la productivité et la satisfaction des clients.
Réduction des temps d’arrêt : En ayant des systèmes hautement disponibles, les temps d’arrêt sont réduits au minimum. Cela permet de limiter les pertes financières, la perte de productivité et les impacts négatifs sur la réputation de l’entreprise.
Évolutivité : La haute disponibilité facilite l’évolutivité des systèmes et des applications. Elle permet d’ajouter de nouvelles ressources, de répartir la charge sur plusieurs serveurs et de gérer efficacement les pics de trafic sans compromettre la disponibilité.
Récupération après sinistre : En cas de catastrophe naturelle, d’incident majeur ou d’autres événements imprévus, la haute disponibilité peut aider à assurer une récupération rapide et efficace des données et des systèmes critiques. Les mécanismes de sauvegarde, de réplication et de basculement automatique permettent de rétablir les services rapidement.
Amélioration de l’expérience utilisateur : Les utilisateurs finaux bénéficient d’une meilleure expérience lorsque les systèmes sont hautement disponibles. Ils peuvent accéder aux services à tout moment, sans interruption, ce qui renforce la confiance dans l’entreprise et augmente la satisfaction client.
Pour atteindre une haute disponibilité, diverses techniques et technologies sont utilisées, telles que la redondance des serveurs, la répartition de la charge, la mise en cluster, la virtualisation, la sauvegarde et la récupération, ainsi que la surveillance et la gestion proactive des pannes.
Le saviez-vous : Il est possible de calculer le pourcentage du temps de disponibilité des systèmes ainsi : X = (n-y) x 100/n.
La haute disponibilité en chiffre
Les pertes financières liées aux temps d’arrêt des systèmes peuvent varier considérablement en fonction de la taille de l’entreprise, du secteur d’activité, de la durée de l’arrêt et de la dépendance de l’entreprise à l’égard des systèmes informatiques. Le coût moyen global d’un incident de sécurité informatique incluent les temps d’arrêt, les coûts de récupération, les pertes de productivité, les pertes de revenus, les dépenses légales et réglementaires, ainsi que l’impact sur la réputation de l’entreprise. Voici quelques chiffres issus d’études passées et d’exemples de temps d’arrêt qui ont couté cher à des entreprises bien connues :
– Étude de l’ITIC (Information Technology Intelligence Consulting) en 2020 : selon cette étude, le coût moyen d’une heure d’arrêt non planifié varie entre 300 000 $ et 400 000 $ pour de grandes entreprises. Les coûts peuvent être beaucoup plus élevés pour les entreprises de plus grande envergure. Selon une étude de l’IDC (International Data Corporation) en 2018, les coûts moyens d’un arrêt imprévu des systèmes variaient de 100 000 $ à 500 000 $ par heure, en fonction de la taille de l’entreprise.
– En 2015, une panne de 12 heures d’un Apple Store a coûté 25 millions de dollars à l’entreprise.
– En août 2016, une panne d’électricité de cinq heures dans un centre des opérations a entraîné l’annulation de 2 000 vols et une perte estimée à 150 millions de dollars pour la compagnie Delta Airlines.
– En mars 2019, une panne de 14 heures a coûté à Facebook quelque 90 millions de dollars.
Ces chiffres doivent être interprétés avec prudence, car ils sont basés sur des études spécifiques et les coûts réels peuvent varier en fonction de nombreux facteurs. Il convient également de noter que les pertes financières ne représentent qu’une partie des impacts d’un temps d’arrêt des systèmes, car il peut également y avoir des conséquences sur la réputation de l’entreprise, la confiance des clients et d’autres aspects non quantifiables.
L’impact de la haute disponibilité sur le Managed File Transfer
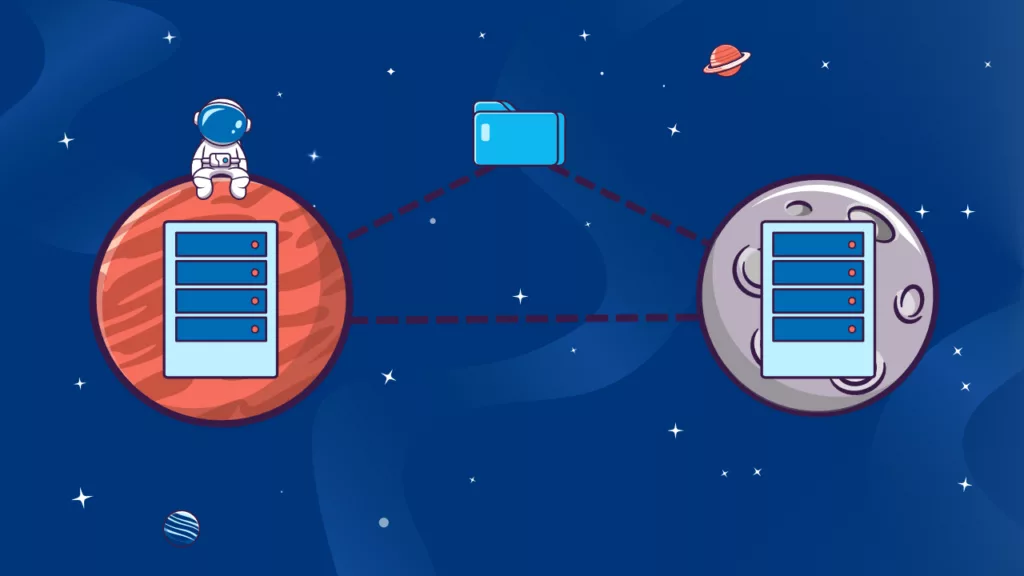
La haute disponibilité (HA) est également essentielle dans le contexte du Managed File Transfer (MFT). Le MFT permet de gérer, sécuriser et automatiser les transferts de fichiers entre différentes entités (serveurs, applications, partenaires commerciaux, etc.).
L’adoption de la haute disponibilité dans le MFT présente beaucoup d’avantages.
Alors pourquoi ne pas profiter du déploiement actif-actif (les 2 nœuds sont actifs en même temps pour se répartir la charge si un des 2 nœuds tombe) de la solution GoAnywhere MFT pour intégrer des solutions hautement disponibles et en cluster, ainsi qu’un second site ?
Avec GoAnywhere, vous disposez d’une fonction d’équilibrage de charge qui distribue de manière fiable les connexions réseau sur vos serveurs de fichiers d’équilibrage de charge et qui est toujours disponible pour vos employés et partenaires commerciaux. En outre, le clustering au sein des workflows garantissent que les charges de travail sont réparties sur plusieurs systèmes pour des performances optimales et un débit accru.


